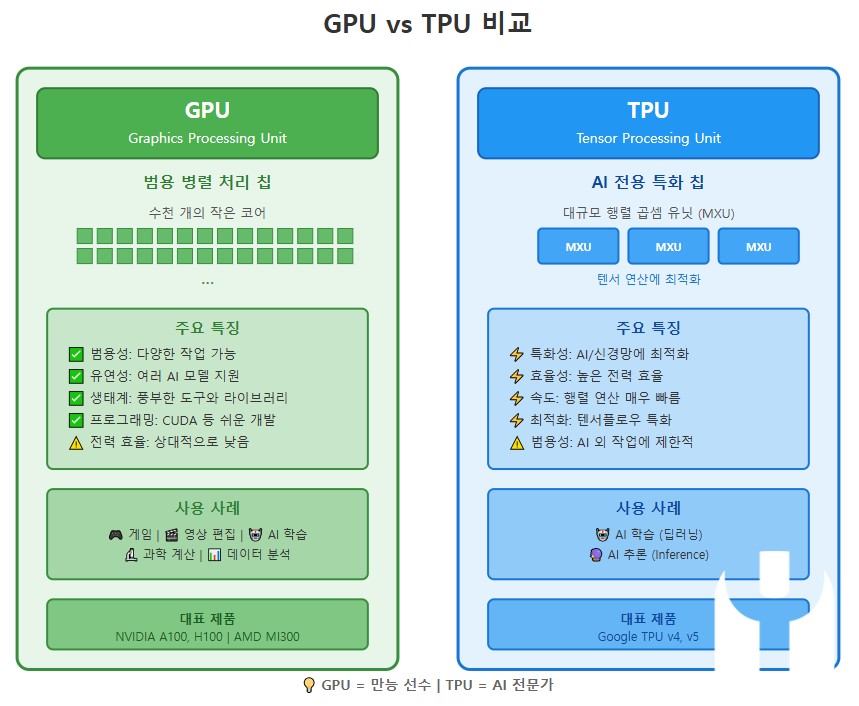
GPU와 TPU는 인공지능 및 고성능 컴퓨팅 분야에서 중요한 역할을 하는 하드웨어 가속기다. GPU는 그래픽 처리 장치로 시작했으나 병렬 처리를 통해 딥러닝 모델 학습에 널리 활용되며, TPU는 구글이 개발한 텐서 처리 유닛으로 머신러닝 작업에 최적화되었다. 이 글은 GPU와 TPU의 아키텍처적 차이와 성능 특성을 비교 분석하고, 최신 연구 결과를 바탕으로 두 기술이 인공지능 생태계에서 갖는 의미를 고찰한다. 이를 통해 머신러닝 모델 개발 및 운영에 적합한 하드웨어 선택에 필요한 실무적 시사점을 도출하고자 한다.
GPU는 복수의 코어를 통해 대규모 병렬 연산을 처리하며, 특히 부동소수점 연산에 강점을 가진다. CUDA와 같은 프레임워크를 통해 다양한 연산에 활용 가능하며, 범용성이 높다. 반면 TPU는 행렬 연산에 특화된 하드웨어로, 낮은 지연시간과 높은 처리량을 제공한다. “The TPU architecture is designed to accelerate dense matrix multiplications and convolutions in neural networks by using systolic arrays that efficiently reuse data” (Jouppi et al., 2017). 즉, TPU는 신경망의 주요 연산인 행렬 곱셈을 효율적으로 처리하기 위해 설계되었다. 이로 인해 특정 머신러닝 작업에서 GPU 대비 에너지 효율성과 처리 속도 면에서 우위를 보인다.
GPU는 그래픽 처리 용도로 개발되었으나, 병렬 처리 능력 덕분에 딥러닝 트레이닝에 널리 활용되며, 다양한 모델과 프레임워크를 지원한다. TPU는 구글의 클라우드 서비스와 밀접하게 연동되어 딥러닝 모델의 추론 및 훈련에 최적화된 환경을 제공한다. 두 장치는 각각 장단점이 있는데, GPU는 높은 유연성과 범용성을 제공하는 반면 TPU는 특정 연산에 특화되어 있어 비용 효율적이다. 또한 TPU는 전력 소비 대비 높은 성능을 보이며 대규모 데이터센터에 적합하다.
최근 연구들은 TPU가 대규모 신경망 학습에서 GPU 대비 2~3배 높은 성능과 에너지 효율을 보인다고 보고한다. 그러나 TPU의 특화된 아키텍처는 범용 연산에는 제한적일 수 있으며, GPU의 풍부한 생태계와 소프트웨어 지원은 여전히 중요한 장점이다. 따라서 하드웨어 선택 시 모델의 특성과 운영 환경, 비용 구조를 종합적으로 고려해야 한다. 특히 TPU는 구글 클라우드 플랫폼 이용 시 최적의 성능을 발휘하므로 클라우드 기반 AI 서비스에 적합하다.
실무적으로는 첫째, 딥러닝 모델이 대규모 행렬 연산에 집중된다면 TPU를 우선 검토하는 것이 효율적이다. 둘째, 다양한 실험과 프로토타입 개발, 혹은 범용 GPU 활용이 필요한 경우 GPU가 적합하다. 셋째, 비용과 전력 효율을 고려해 데이터센터 운영 환경에 따라 하드웨어를 선택해야 한다. 넷째, 클라우드 서비스와 연계된 TPU 사용은 신속한 배포와 확장성을 제공한다는 점을 유념해야 한다. 마지막으로 소프트웨어 생태계와 개발자 지원 체계를 충분히 검토하는 것이 성공적인 AI 프로젝트 수행에 필수적이다.
GPU와 TPU는 각기 다른 설계 철학과 강점을 지니고 있어, 인공지능 모델 개발과 운영에서 상호 보완적인 역할을 한다. 최적의 하드웨어 선택은 모델의 특성과 워크로드, 비용 및 에너지 효율성을 균형 있게 고려하는 데서 출발한다. 이러한 분석은 AI 하드웨어 선택의 전략적 판단에 실용적 가이드를 제공한다.
참고문헌
Jouppi, N. P., Young, C., Patil, N., Patterson, D., Agrawal, G., Bajwa, R., … & Yoon, D. H. (2017). In-datacenter performance analysis of a tensor processing unit. *Proceedings of the 44th Annual International Symposium on Computer Architecture*, 1-12.